Welcome to our hands-on guide on effortlessly extracting restaurant data from Yelp using the Scrapenetwork web scraping api free. Are you tired of the technical jargon and complications that come with web scraping? Look no further. We’ve streamlined the process to make it accessible to both tech enthusiasts and those without a technical background.
Here’s what you can expect from this comprehensive guide:
- Free & Powerful: Use Scrapenetwork Api at no cost.
- Easy for Everyone: Learn to scrape Yelp using Google Sheets & AppScripts, no tech skills are needed.
- Tackle Tech Barriers: Bypass IP blocks and proxy challenges effortlessly.
- Master Web Scraping: Use Scrapenetwork Api to become a scraping pro.
So, gear up, and let’s transform your Yelp data scraping experience using Scrapenetwork!
Why choose Scrapenetwork?
- Forget Technical Roadblocks: With Scrapenetwork, you can sidestep IP blocks and proxy issues. No more technical hitches.
- Simplicity at Its Best: An intuitive interface designed for all, ensuring you spend time on what’s important – getting the data you need.
- Jump Right In: Begin your data exploration with 5,000 free credits on signup. Yes, free.
Dive in, and let’s make web scraping on Yelp a breeze with Scrapenetwork!
Step 1: Sign up for the “Scrapenetwork” API:
Welcome to the realm of data exploration! To begin your exciting journey, head over to the Scrapenetwork website and sign up for an account. In mere moments, you will gain access to Scrapenetwork’s powerful API services, unleashing a world of possibilities for your data scraping endeavors.
Step 2: Get the API Key:
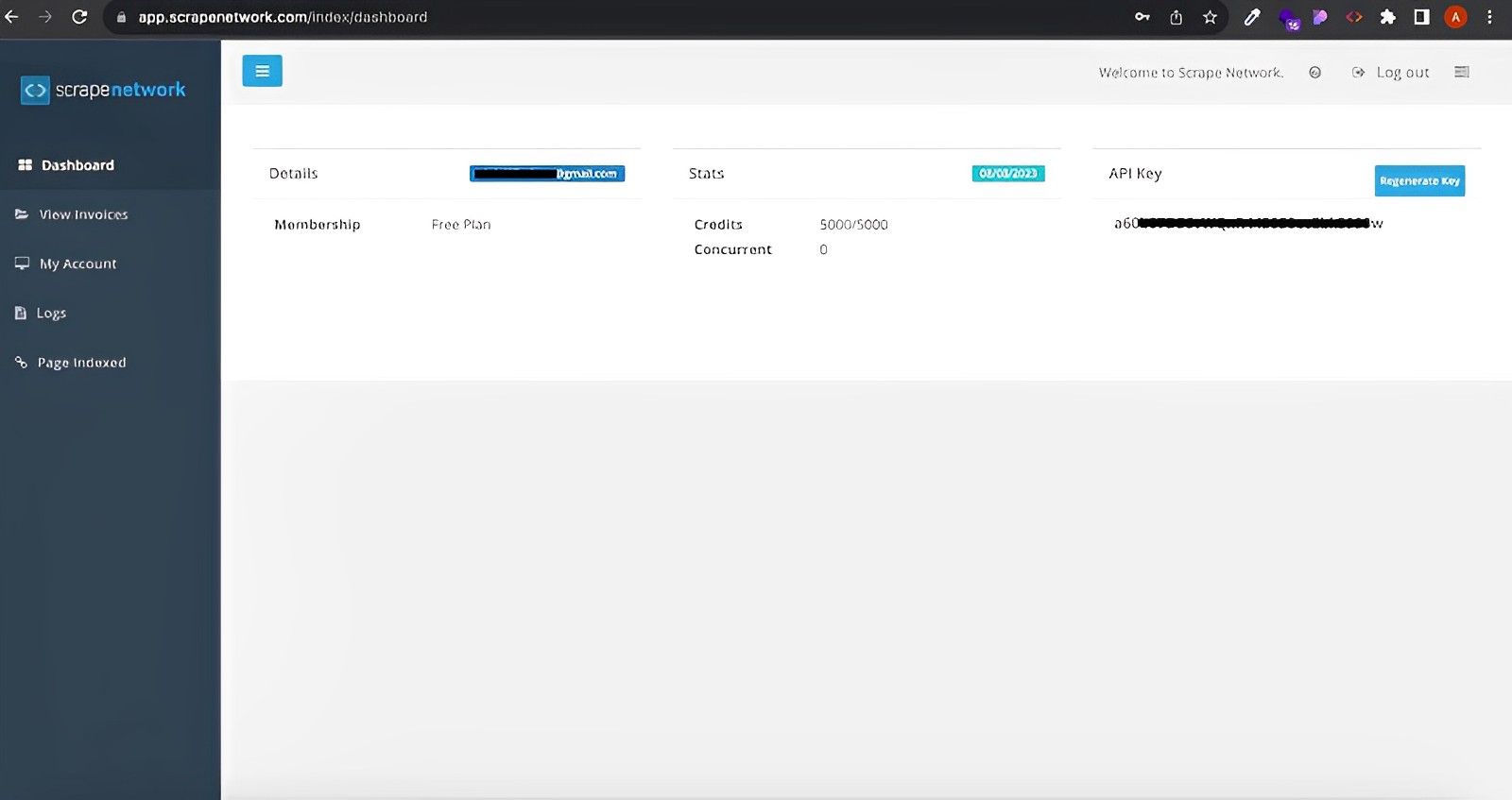
Upon successful registration, navigate to your dashboard on Scrapenetwork. There, you will find your unique API key. Make sure to note it down securely, as you’ll need it for the subsequent steps in the scraping process.
Here is where you get your API key:
Step 3: Identify the Target Webpage:
To begin web scraping, you need to identify the specific webpage from which you want to extract data. In this guide, we’ll embark on an exciting quest to scrape data from the renowned “yelp.com” website.
Yelp Search Results:

For this example, let’s say our goal is to extract information about restaurants in New York City from Yelp.
Example URL: https://www.yelp.com/search?find_desc=restaurants&find_loc=New+York+City%2C+NY
In this example URL, we can identify the following components and variables:
- ‘https://www.yelp.com/search’ This is the base URL for Yelp’s search page.
- find_desc=restaurants: This parameter specifies the search term for the type of businesses we’re looking for, in this case, “restaurants”.
- find_loc=New+York+City%2C+NY: This parameter defines the location for the search, in this case, “New York City, NY”.
You can modify the find_desc and find_loc parameters in the URL to target different search results based on your specific needs. For instance, you can change the search term to “hotels” or the location to “Los Angeles, CA.”
Moving on, we separated this tutorial into two sections, one for tech-savvy people and one for non-technical people. For non-technical people, we’ll show you step by step how to scrape Yelp using Google Sheets’ Appscript extension with a simple plug and play script that will export that data to your active Google Sheet. For technical people, we’ll show you how to do the same using Python and with cheerio library.
– If you are not a tech person, proceed to the next step; otherwise, you can skip step 4A.
Step 4 A: Non-Technical Guide to Web Scraping using Google Sheets
If you’re a non-technical user looking to scrape Yelp data for restaurants in New York and analyze it in Google Sheets, you’re in the right place. Follow this simple guide to extract valuable information for free using the ScrapeNetwork API.
# 1: Define Your Objectives:
Clearly outline what specific data you want to extract. Decide which information is valuable for your analysis, such as business names, categories, ratings, number of reviews, location, and business details page urls. Determine the Yelp search page URL you’ll be scraping data from. For instance, if you’re interested in restaurants in New York, you might start with Yelp’s search results for that location.
# 2: Set Up Your Google Sheets
Open Google Sheets (sheets.google.com) and create a new blank spreadsheet. Name that sheet Scraping101
# 3: Install Google Sheets Script
In your Google Sheets document, click on “Extensions” > “Apps Script.”
Remove the default code and paste the script we provided (detailed below).
Note: Replace the “YOUR_API_KEY” text with your free Scrapenetwork API key from the dashboard.
function scrapeYelpAndUploadToGoogleSheets() {
var url = var url = 'https://app.bankstatementpdfconverter.com/api?api_key=YOUR_API_KEY&request_url=https://www.yelp.com/search?find_desc=Restaurants&find_loc=New+York';var response = UrlFetchApp.fetch(url, {'muteHttpExceptions': true});
var content = response.getContentText();
// Use Cheerio.js for parsing HTML
var $ = Cheerio.load(content);
var data_list = [];
$("div[class*=container]").each(function() {
try {
if ($(this).find("h3").length > 0) {
var item = $(this);
var rating = "-";
var review = "-";
var price = "-";
var address = "-";
var category_names = "-";
var link = "";
var head_name = item.find("h3").text().trim();
var first_div = item.find("div.display--inline-block__09f24__fEDiJ.border-color--default__09f24__NPAKY");
if (first_div.find("span.css-gutk1c").length > 0) rating = first_div.find("span.css-gutk1c").text();
if (first_div.find("span.css-chan6m").length > 0) review = first_div.find("span.css-chan6m").text();
// Address extraction
var address_lines = [];
var first_p = item.find("p.css-dzq7l1, div.mainAttributes__09f24__bQYNE.arrange-unit__09f24__rqHTg.arrange-unit-fill__09f24__CUubG.border-color--default__09f24__NPAKY");
if (first_p.find("span.css-chan6m").length > 0) {
var total = first_p.find("span.css-chan6m");
address = total.last().text().trim();
} else if (item.find('address').length > 0 || item.find('p.css-1txce9h').length > 0) {
var address_list = item.find('p.css-1txce9h');
address_list.each(function() {
var line = $(this).text().trim();
if (line) {
address_lines.push(line);
}
});
}
if (address_lines.length > 0) {
address = address_lines.join(", ");
}
if (item.find("span.priceRange__09f24__mmOuH.css-1s7bx9e").length > 0) {
price = item.find("span.priceRange__09f24__mmOuH.css-1s7bx9e").text();
}
var categories_list = [];
var categorySpan = item.find("span.display--inline__09f24__c6N_k.border-color--default__09f24__NPAKY");
categorySpan.find("a.css-abnp9g").each(function() {
categories_list.push($(this).text());
});
category_names = categories_list.join(", ");
if (item.find("h3").find("a").length > 0) link = "https://www.yelp.com" + item.find("h3 a").attr('href');
data_list.push([head_name, category_names, rating, review, price, address, link]);
}
} catch (e) {
console.error("Error:", e);
}
});
// Write data to Google Sheet
var sheet = SpreadsheetApp.getActiveSpreadsheet().getActiveSheet();
sheet.clear();
sheet.appendRow(["Business name", "Category", "Rating", "Reviews", "Price Range", "Location", "Business Details Link"]);
sheet.getRange(2, 1, data_list.length, 7).setValues(data_list);
Logger.log("Data has been written to Google Sheet");
}
Copy and paste the above into this text box:

# 4: Install the Cheerio Library:
You can install the Cheerio library for Google Apps Script by following the instructions here:
Select “Resources” > “Libraries…” in the Google Apps Script editor. Enter the project key (1ReeQ6WO8kKNxoaA_O0XEQ589cIrRvEBA9qcWpNqdOP17i47u6N9M5Xh0) in the “Find a Library” field, and choose “Select”. (If you have copied the library, enter instead the project key of your copy.). After this, press the Add button, and the library will be added.

# 5: Run the script by pressing the run icon

Save your script, and Close the Apps Script editor.
# 6: Enjoy the Scraped Data
Once the script runs successfully, go back to your Google Sheets. You’ll find the scraped Yelp data neatly organised in your specified columns.
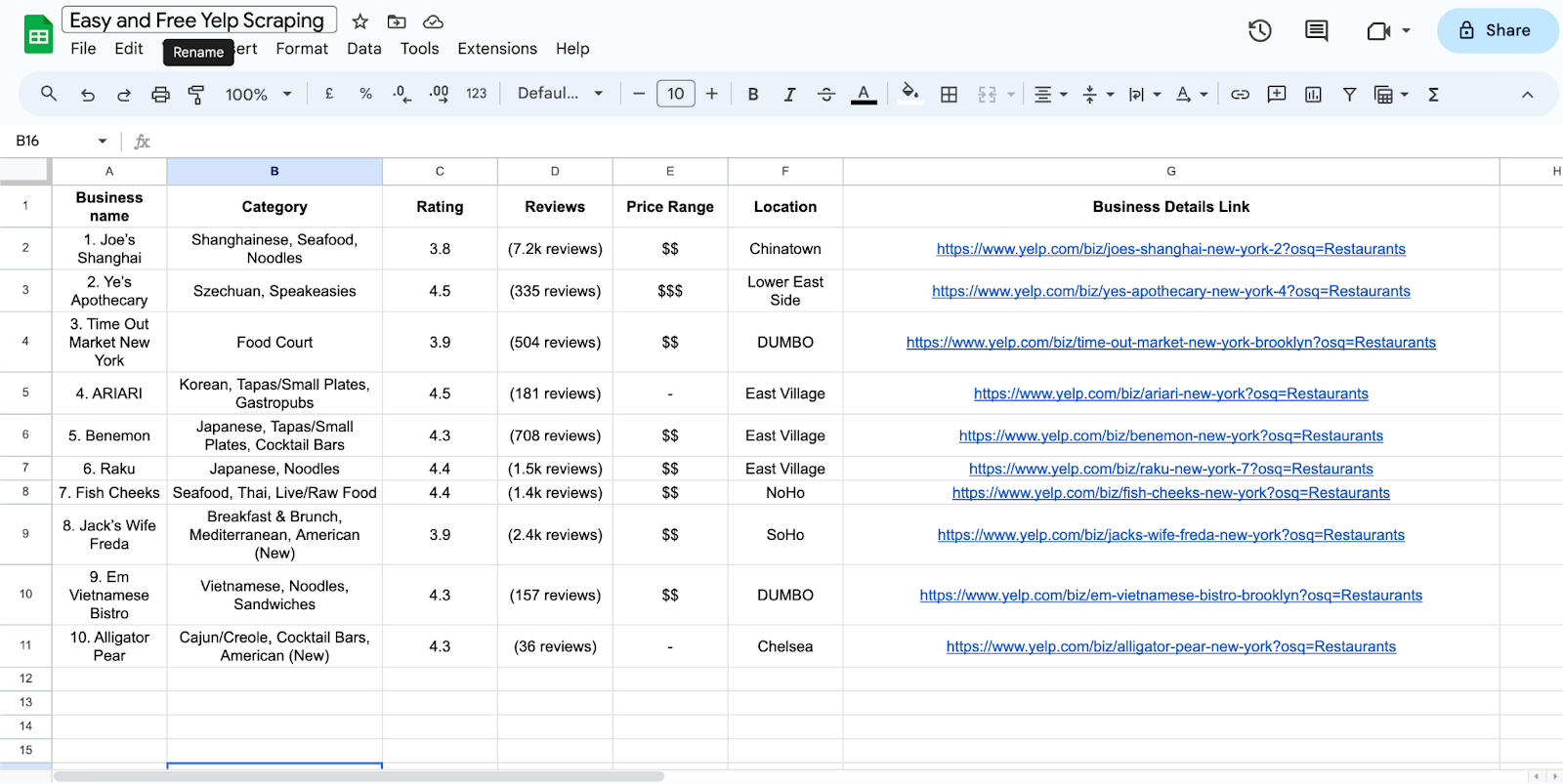
# 7: Analyze the Data
Utilize Google Sheets’ features to analyze and visualize your scraped Yelp data.
Create charts, graphs, or pivot tables to gain insights.
Congratulations! You’ve successfully scraped Yelp data for restaurants in New York and analyzed it in Google Sheets, all without any technical expertise.
Step 4B: Technical Guide to Web Scraping Using the Scrapenetwork API:
Welcome to the Technical Guide to Web Scraping Using the Scrapenetwork API. In this guide, we will take you through a simple and free solution for web scraping. Web scraping can be done using various languages, like Java and PHP. However, for the purpose of this guide, we will be focusing on Python. By leveraging Python and the Beautiful Soup library with the scrapenetwork API, we’ll demonstrate how to extract valuable information from HTML and XML files. This guide is designed to be beginner-friendly, assuming no prior experience in web scraping, and aims to provide clear and easy-to-follow steps.
# 1: Install Python 3
- Open your web browser and navigate to https://www.python.org/downloads/.
- Download the latest version of Python 3 suitable for your operating system (Windows, macOS, or Linux).
- Run the downloaded installer.
- During installation, ensure the option “Add Python x.x to PATH” (x.x being the version number) is selected.
Complete the installation by clicking “Install Now.”
# 2: Verify Python Installation
- Open a terminal or command prompt on your computer.
- Type the following command and press Enter to verify Python 3
python3 –version
# 3: Install Homebrew (if needed)
If you’re using macOS or Linux and do not have Homebrew installed, you can install it by following the instructions on the Homebrew website: https://brew.sh/
# 4: Install pip3 Using Homebrew
- Open a terminal and run the following command to install pip3:
brew install python3
This command installs Python 3 along with its associated tools, including pip3.
# 5: Verify pip3 Installation
After the pip3 installation is complete, verify its installation by running:
pip3 –version
# 6: Install the Request Library
In the terminal, use pip3 to install the requests library:
pip3 install requests
# 7: Install Beautiful Soup
- Open your preferred code editor and create a new folder for your project.
- In the terminal, navigate to the project folder and use pip3 to install Beautiful Soup:
pip3 install beautifulsoup4
Before moving on and writing the code to scrape, we first need to identify the data we have to scrape.
# 8: Identify the Data to Scrape using CSS Selectors:
In this step, we’ll identify the data elements on the Yelp search results page that we want to scrape. For our example, let’s say we want to extract the following information for each restaurant:
- Business Name(Restaurant Name)
- Category(Cuisine)
- Rating (out of 5 stars)
- Reviews
- Location
- Business Details Url
To do this, we’ll use CSS selectors to target the corresponding HTML elements.
Example CSS Selectors:
- Restaurant Name:
h3 > span a.[class*=css-]
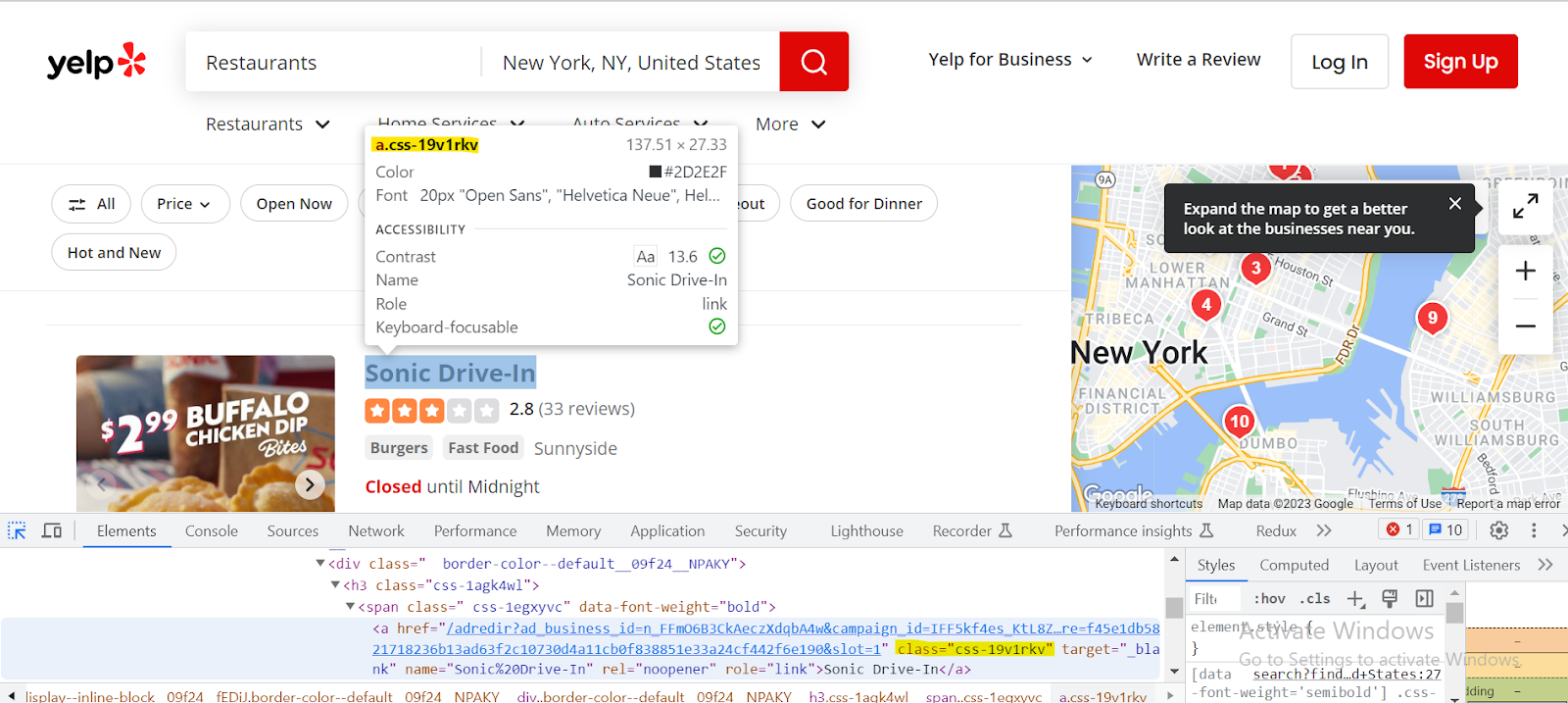
- Category:
span a[class*= css-abnp9g] > button[class*= css-1iacdop]
- Rating (out of 5 stars):
span[class*= css-gutkic]

- Locations:
div[class*=container__09f24__21w3G] > span[class*=css-chan6m]

Using these CSS selectors, we can extract the desired data from each restaurant listing on the Yelp search results page.
# 9: The Code
Here’s an example code snippet in Python using BeautifulSoup to scrape the data from Yelp search results page for Restaurants in New York City using your ScrapeNetwork Free API.
Note: Replace the “YOUR_API_KEY” text with your free Scrapenetwork API key from the dashboard.
import json
import csv
import requests
from bs4 import BeautifulSoup
URL = "https://app.bankstatementpdfconverter.com/api?api_key=YOUR_API_KEY&request_url=https://www.yelp.com/search?find_desc=Restaurants&find_loc=New+York"
r = requests.get(URL)
parsed_page = BeautifulSoup(r.text, "html.parser")
data_list = []
page_jsons = []
for item in parsed_page.select("[class*=container]"):
try:
if item.find_all("h3"):
div_list = item.find_all("h3")
for index, head in enumerate(div_list):
first_div = item.find(
"div",
class_="display--inline-block__09f24__fEDiJ border-color--default__09f24__NPAKY",
)
rating = "-"
review = "-"
if first_div.find("span", class_="css-gutk1c"):
rating = (
first_div.find("span", class_="css-gutk1c").get_text() or "-"
)
if first_div.find("span", class_="css-chan6m"):
review = (
first_div.find("span", class_="css-chan6m").get_text() or "-"
)
price = "-"
address = "-"
address_list = []
address_lines = []
first_p = first_div
if item.find("p", class_="css-dzq7l1"):
first_p = item.find("p", class_="css-dzq7l1")
if item.find('div',class_='mainAttributes__09f24__bQYNE arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG border-color--default__09f24__NPAKY'):
first_p = item.find('div',class_='mainAttributes__09f24__bQYNE arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG border-color--default__09f24__NPAKY')
if first_p.find("span", class_="css-chan6m"):
total = first_p.find_all("span", class_="css-chan6m")
address = total[-1].get_text()
if item.find('address'):
address_list = item.find_all('p',class_='css-1txce9h')
for line in address_list:
if line.get_text():
address_lines.append(line.get_text())
if first_p.find("span", class_="priceRange__09f24__mmOuH css-1s7bx9e"):
price = (
first_p.find(
"span", class_="priceRange__09f24__mmOuH css-1s7bx9e"
).get_text()
or "-"
)
category_names = "-"
categories_list = []
if first_p.find(
"span",
class_="display--inline__09f24__c6N_k border-color--default__09f24__NPAKY",
):
categorySpan = first_p.find(
"span",
class_="display--inline__09f24__c6N_k border-color--default__09f24__NPAKY",
)
if categorySpan:
if categorySpan.find_all("a", class_="css-abnp9g"):
categories = categorySpan.find_all("a", class_="css-abnp9g")
for category in categories:
if category.get_text():
categories_list.append(category.get_text())
head_name = item.find("h3").get_text()
# print(head_name)
link = ''
if item.find("h3").find("a"):
link = item.find('h3').find('a').get('href')
if item.find('span',class_='css-1egxyvc'):
link = item.find('span',class_='css-1egxyvc').find('a').get('href')
link = "https://www.yelp.com" + link
address_string = ''
category_names = ", ".join(categories_list)
if len(address_lines) > 0:
address = ", ".join(address_lines)
print("----------")
print(head_name)
print(link)
print(rating)
print(review)
print(price)
print(address)
print(category_names)
data_list.append(
[head_name, category_names, rating, review, price, address, link]
) # here comes the row data that is populated beneath each header, pattern must be maintained w.r.t headers/column titles
except Exception as e:
raise e
csv_file = "restaurant_data.csv"
with open(csv_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(
[
"Business name",
"Category",
"Rating",
"Reviews",
"Price Range",
"Location",
"Business Details Link",
]
) # Write headers/column titles
writer.writerows(data_list)
print(f"Data has been written to {csv_file}")
TIP: Just make sure you have the correct format (we would recommend using the black formatter for Python).
And after saving the code, go to the terminal to run the file by typing this command:
Python3 scrapenetworkApi.py
You will be able to see this output:
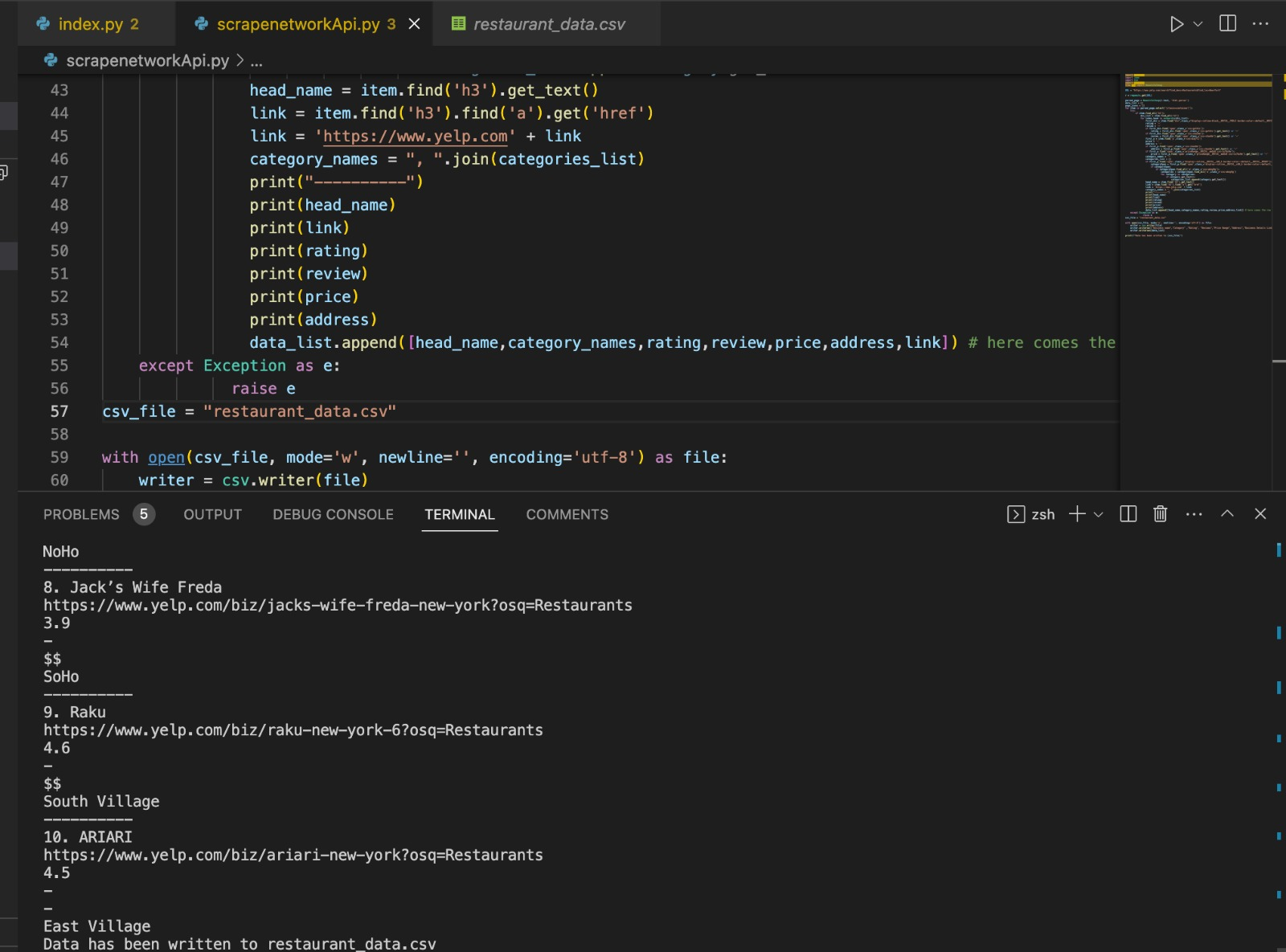
The data is extracted and successfully saved in the csv format:

Now that we have our data extracted, it’s finally time to export it and visualize it on Google Sheets.
# 10: Easily Export Extracted Data on Google Sheets:
In this step, we’ll provide you with a glimpse of how your extracted data will appear on Google Sheets. Since we’ve already transformed the extracted data into a CSV format, we’ll proceed by importing it into a Google Sheets file. Let’s take a look at the simple and elegant representation of your data on a sheet:
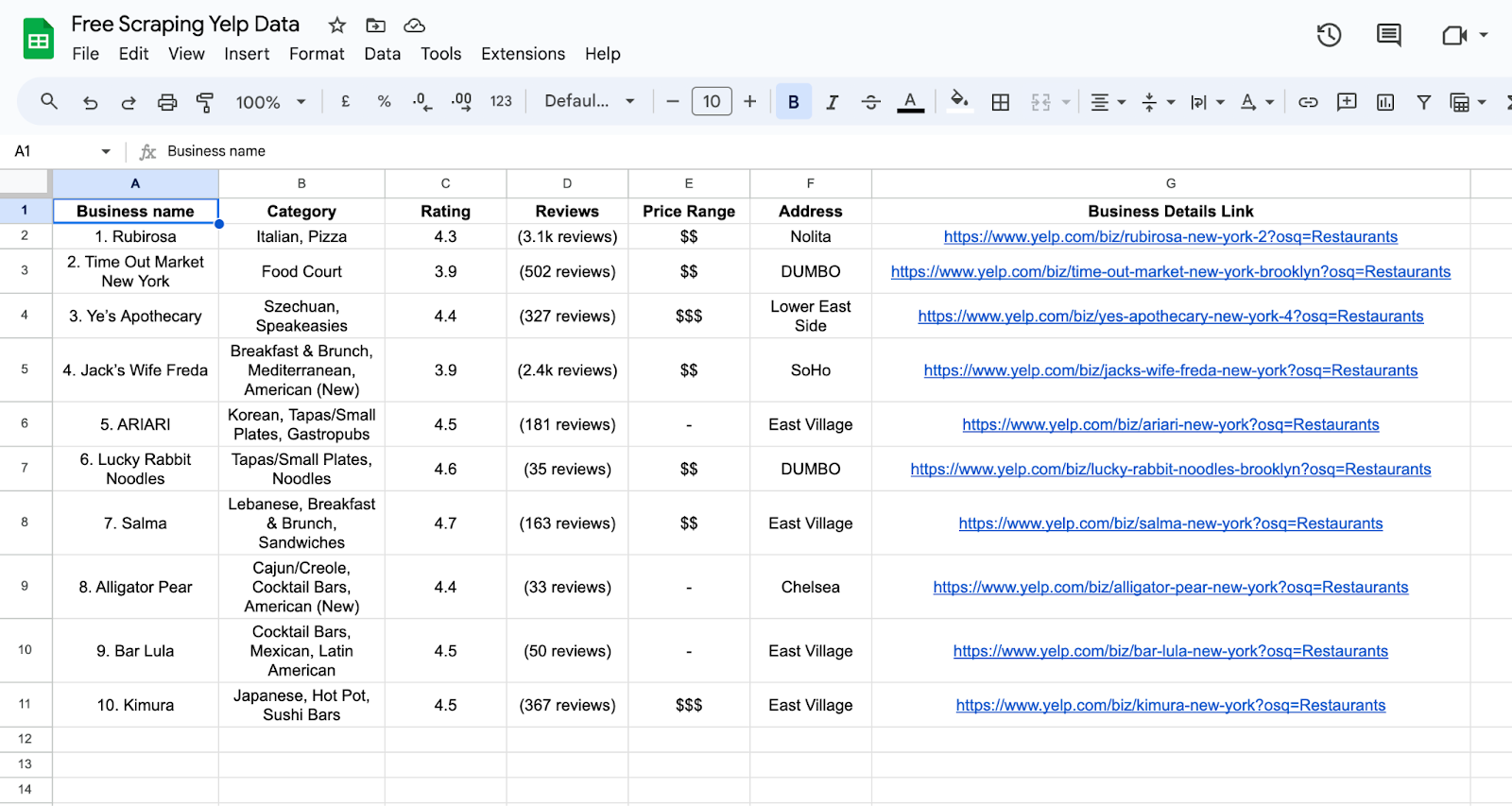
This visual representation on Google Sheets allows you to view your scraped data in an organized and structured manner. The CSV format seamlessly translates into rows and columns on Google Sheets, enabling you to quickly analyze, sort, and manipulate the information as needed.
By integrating web scraping with the power of Google Sheets, you’re able to harness the benefits of both techniques to enhance your data exploration and decision-making processes. This synergy empowers you to extract, manage, and visualize data efficiently, making it a valuable asset for various projects and analyses.
Frequently Asked Questions (FAQ)
How can I scrape Yelp’s data for free?
With Scrapenetwork web scraping api, you can access and scrape Yelp data for free. You can sign up here and get 5,000 free API credits per month (with a maximum of 5 concurrent connections), allowing you to retrieve Yelp data without any initial cost.
Can I use Scrapenetwork to scrape Yelp’s data?
Absolutely! Scrapenetwork offers a reliable scraping API that enables you to extract Yelp data and other web content effectively. With Scrapenetwork’s API, you can collect data from Yelp listings, reviews, business details, and more.
Can I use the ScrapeNetwork API for commercial purposes?
Yes, you can use the ScrapeNetwork API for commercial purposes. Web scraping of publicly available data that is not behind a password is generally legal and permissible for anyone to review or use.
Conclusion
In conclusion, this guide has equipped you with a very easy and clear understanding of web scraping using the Scrapenetwork API and data parsing through Python and Beautiful Soup. By following these step-by-step instructions, you’ve learned how to easily extract, structure, and save data in a CSV format for free using the Scrapenetwork API.